

Publicado por Chris Wailes, ingeniero de software sénior

El rendimiento, la seguridad y la productividad de los desarrolladores que proporciona Rust han llevado a un rápido desarrollo. adopción En el plataforma Android. De Los tiempos de construcción más lentos son una preocupación. Cuando utilizamos Rust, especialmente dentro de un proyecto grande como Android, hemos trabajado para proporcionar la versión más rápida posible de la cadena de herramientas de Rust. Para hacer esto, aprovechamos múltiples formas de creación de perfiles y optimización, así como ajustes de C/C++, enlazadores y indicadores de Rust. Gran parte de lo que voy a describir es similar al proceso de compilación de las versiones oficiales de la cadena de herramientas de Rust, pero adaptado a las necesidades específicas del código base de Android. Espero que esta publicación sea informativa en general y, si es mantenedor de una cadena de herramientas de Rust, pueda hacerle la vida más fácil.
Compiladores de Android
Si bien Android ciertamente no es el único que necesita una cadena de herramientas de compilación cruzada de alto rendimiento, este hecho, combinado con la gran cantidad de invocaciones diarias de compilación de Android, significa que debemos equilibrar cuidadosamente las compensaciones entre el tiempo que lleva construir una cadena de herramientas, el tamaño de la cadena de herramientas y rendimiento del compilador del producto.
Nuestro proceso de construcción
Para ser claros, las optimizaciones que se enumeran a continuación también están presentes en las versiones de rusticc obtenidas mediante óxido. Lo que diferencia la cadena de herramientas de Android de las versiones oficiales, además de su procedencia, son los objetivos de compilación cruzada disponibles y la base de código utilizada para la creación de perfiles. Todos los números de rendimiento que se enumeran a continuación representan el tiempo que lleva construir los componentes Rust de una imagen de Android y es posible que no reflejen la aceleración al compilar otras bases de código con nuestra cadena de herramientas.
Unidad Codegen (CGU1)
Cuando Rust compila una caja, la divide en varias unidades de generación de código. Cada fragmento de código independiente se genera y optimiza simultáneamente y posteriormente se recombina. Este enfoque permite a LLVM procesar cada unidad de generación de código por separado y mejora los tiempos de compilación, pero puede reducir el rendimiento del código generado. Parte de este rendimiento se puede recuperar mediante el uso de Link Time Optimization (LTO), pero no se garantiza que obtenga el mismo rendimiento que si la caja se compilara en una sola unidad codegen.
Para exponer tantas oportunidades de optimización como sea posible y garantizar compilaciones reproducibles, agregamos la opción -C codegen-units=1 a la variable de entorno RUSTFLAGS. Esto reduce el tamaño de la cadena de herramientas en aproximadamente un 5,5 % y al mismo tiempo aumenta el rendimiento en aproximadamente un 1,8 %.
Tenga en cuenta que configurar esta opción reducirá el tiempo necesario para construir la cadena de herramientas en aproximadamente 2 veces (medido en nuestras estaciones de trabajo).
Secciones GC
Muchos proyectos, incluida la cadena de herramientas de Rust, tienen funciones, clases o incluso espacios de nombres completos que no son necesarios en determinados contextos. La opción más segura y sencilla es dejar estos objetos de código en el producto final. Esto aumentará el tamaño del código y puede reducir el rendimiento (debido a problemas de diseño y almacenamiento en caché), pero nunca debería resultar en un binario compilado o vinculado incorrectamente.
Es posible, sin embargo, para pedirle al vinculador que elimine objetos de código a los que la función main() no hace referencia transitivamente usando el argumento del vinculador –gc-sections. El vinculador solo puede funcionar por sección, por lo que si hace referencia a un objeto en una sección, debe conservar la sección completa. Es por eso que también es común pasar las opciones -ffunction-sections y -fdata-sections al compilador o al backend de generación de código. Esto garantizará que a cada objeto de código se le asigne una sección independiente, lo que permitirá que el paso de recolección de basura del vinculador recopile objetos individualmente.
Esta es una de las primeras optimizaciones que implementamos y, en ese momento, resultó en un ahorro de tamaño significativo (del orden de cientos de MiB). Sin embargo, la mayoría de estos beneficios han sido subsumidos por los logrados al configurar -C codegen-units=1 cuando se usan en combinación, y ahora no hay diferencia entre las dos cadenas de herramientas producidas en términos de tamaño o rendimiento. Sin embargo, debido a la sobrecarga adicional, no siempre utilizamos CGU1 al construir la cadena de herramientas. Al verificar la corrección, la velocidad final del compilador es menos importante y, como tal, permitimos que la cadena de herramientas se cree con el número predeterminado de unidades codegen. En estas situaciones, todavía ejecutamos la sección GC al conectarnos, ya que ofrece algunos beneficios de rendimiento y tamaño a un costo muy bajo.
Optimización del tiempo de enlace (LTO)
Un compilador sólo puede optimizar las funciones y los datos que puede ver. Crear una biblioteca o un ejecutable a partir de archivos objeto o bibliotecas independientes puede acelerar la compilación, pero a costa de optimizaciones que dependen de la información disponible sólo cuando se ensambla el binario final. La optimización del tiempo de enlace le da al compilador otra oportunidad de analizar y modificar el binario durante el enlace.
Para la cadena de herramientas de Android Rust que ejecutamos LTO delgado tanto el código C++ en LLVM como el código Rust que conforma el compilador y las herramientas de Rust. Dado que el IR emitido por nuestro clang puede ser una versión diferente del IR emitido por rusticc, no podemos ejecutar LTO multilingüe ni vincularnos estáticamente con libLLVM. Sin embargo, las mejoras de rendimiento al usar una biblioteca compartida optimizada para LTO son mayores que las de usar una biblioteca estática no optimizada para LTO, por lo que elegimos usar enlaces compartidos.
El uso de secciones CGU1, GC y LTO produce una aceleración de aproximadamente un 7,7 % y una mejora de tamaño de aproximadamente un 5,4 % en comparación con la línea base. Esto da como resultado una aceleración de aproximadamente el 6% en comparación con la fase anterior del gasoducto, debido exclusivamente a LTO.
Optimización basada en perfiles (PGO)
Los argumentos de la línea de comando, las variables de entorno y el contenido del archivo pueden afectar la forma en que se ejecuta un programa. Algunos bloques de código pueden usarse con frecuencia, mientras que otras ramas y funciones solo pueden usarse cuando ocurre un error. Al crear un perfil de una aplicación durante su ejecución, podemos recopilar datos sobre la frecuencia con la que se ejecutan estos bloques de código. Estos datos se pueden utilizar para guiar las optimizaciones al recompilar el programa.
Usamos binarios instrumentados para recopilar perfiles tanto de la creación de la cadena de herramientas de Rust como de la creación de los componentes Rust de las imágenes de Android para x86_64, aarch64 y riscv64. Luego, estos cuatro perfiles se combinan y la cadena de herramientas se vuelve a compilar con optimizaciones basadas en perfiles.
Como resultado, la cadena de herramientas logra una aceleración de aproximadamente el 19,8 % y una reducción de tamaño del 5,3 % en comparación con el compilador básico. Este es un aumento de velocidad del 13,2% con respecto a la etapa anterior del compilador.
BOLT: herramienta de optimización y diseño binario
Incluso con LTO habilitado, el vinculador todavía tiene control del diseño del binario final. Dado que no se guía por ninguna información de perfil, el vinculador podría colocar accidentalmente una función que se llama con frecuencia (activa) junto a una función que rara vez se llama (fría). Cuando posteriormente se llame a la función activa, todas las funciones se cargarán en la misma página de memoria. Las funciones frías ahora ocupan espacio que podría asignarse a otras funciones activas, lo que obliga a cargar páginas adicionales que contienen estas funciones.
TORNILLO mitiga este problema mediante el uso de un conjunto adicional de información de creación de perfiles centrada en el diseño para reorganizar funciones y datos. Para acelerar Rustc, perfilamos libLLVM, libstd y librustc_driver, que son las principales dependencias del compilador. Luego, estas bibliotecas se optimizan con BOLT utilizando las siguientes opciones:
–peepholes=todos –data=
Cualquier biblioteca adicional correspondiente a lib/*.so se optimiza sin perfiles usando solo –peepholes=all.
La aplicación de BOLT a nuestra cadena de herramientas produce una aceleración con respecto al compilador de referencia de aproximadamente un 24,7 % con un aumento de tamaño de aproximadamente un 10,9 %. Esto es aproximadamente un 6,1% de aceleración con respecto al compilador PGO sin BOLT.
Si está interesado en usar BOLT en su proyecto/compilación, le ofrezco estas dos recomendaciones: 1) necesitará emitir información de reubicación adicional en sus binarios usando el argumento del enlazador -Wl,–emit-relocs y 2) use el mismo entrada de la biblioteca al llamar a BOLT para producir las versiones instrumentadas y optimizadas.
Conclusión
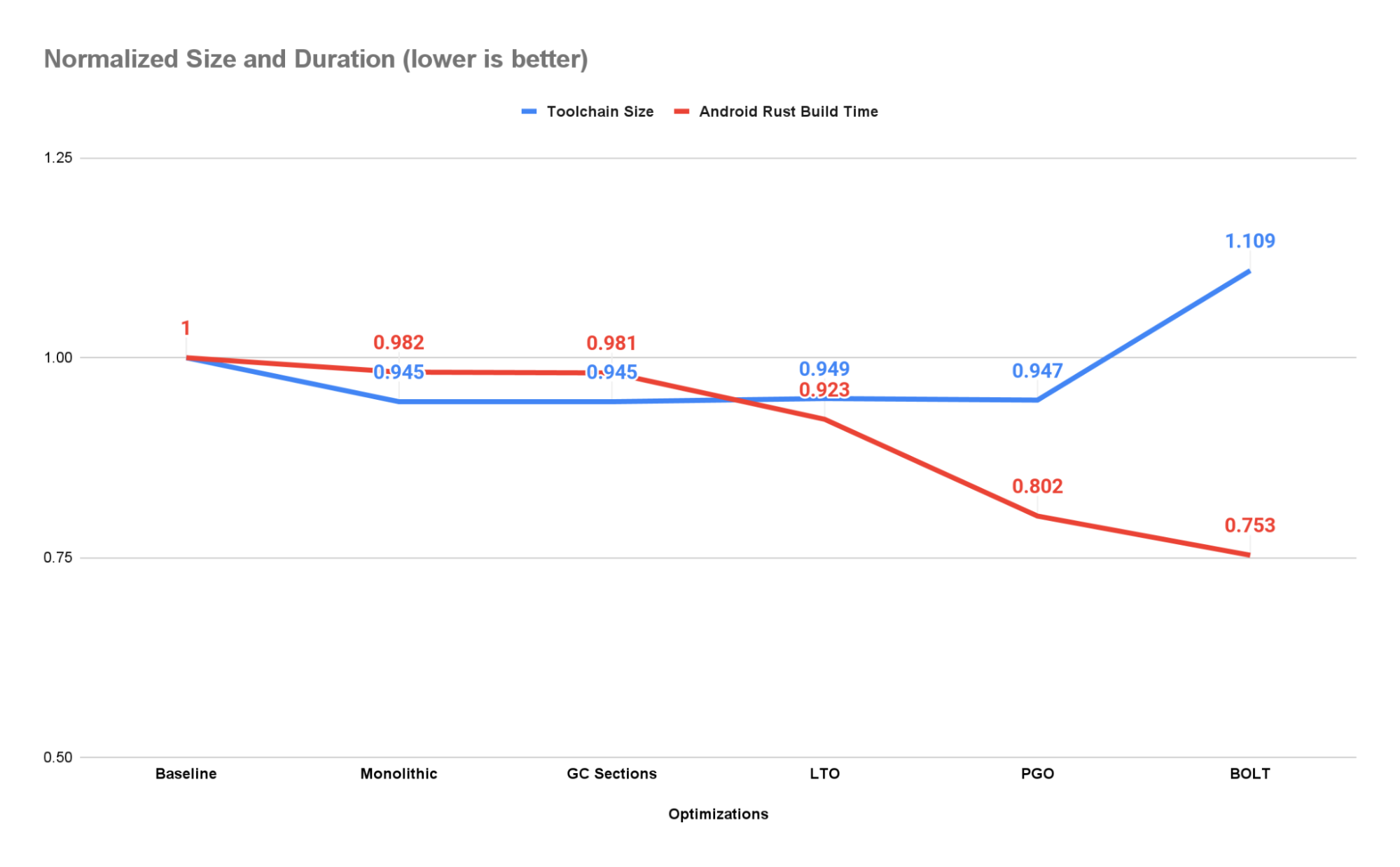
Al compilar como una única unidad de generación de código, recopilar datos basura, realizar optimizaciones basadas en el tiempo de enlace y el perfil y aprovechar la herramienta BOLT, pudimos acelerar el tiempo que lleva compilar los componentes de Android Rust en 24.8. %. Por cada 50.000 compilaciones de Android ejecutadas por día en nuestra infraestructura de CI, ahorramos aproximadamente 10.000 horas de ejecución en serie.
Nuestra industria no se queda quieta y definitivamente habrá otra herramienta y otro conjunto de perfiles para recopilar en el futuro cercano. Hasta entonces, seguiremos realizando mejoras incrementales en la búsqueda de rendimiento adicional. ¡Feliz programación!

