En este artículo, veremos el desarrollo de la IA y el campo del aprendizaje profundo. El aprendizaje profundo se originó en la era de las computadoras de tubo. En 1958, Frank Rosenblatt de la Universidad de Cornell diseñó la primera red neuronal artificial. Esto más tarde se llamó “aprendizaje profundo”. Rosenblatt sabía que esta tecnología superaba el poder de cómputo en ese momento. Dijo… “A medida que aumentan los nodos de conexión de la red neuronal… las computadoras digitales tradicionales pronto ya no podrán manejar la carga computacional”.

Afortunadamente, el hardware de las computadoras ha mejorado rápidamente a lo largo de las décadas. Esto hace que los cálculos sean unas 10 millones de veces más rápidos. Como resultado, los investigadores del siglo XXI pueden implementar redes neuronales. Ahora hay más conexiones para simular fenómenos más complejos. Hoy en día, el aprendizaje profundo ha sido ampliamente utilizado en varios campos. Se ha utilizado en juegos, traducción de idiomas, análisis de imágenes médicas, etc.
El auge del aprendizaje profundo es fuerte, pero es probable que su futuro sea difícil. Las limitaciones computacionales que preocupan a Rosenblatt siguen siendo una nube que se cierne sobre el campo del aprendizaje profundo. Hoy en día, los investigadores de aprendizaje profundo están superando los límites de sus herramientas informáticas.
Cómo funciona el aprendizaje profundo
El aprendizaje profundo es el resultado del desarrollo a largo plazo en el campo de la inteligencia artificial. Los primeros sistemas de IA se basaban en la lógica y las reglas proporcionadas por expertos humanos. Gradualmente, ahora hay parámetros que podrían ajustarse a través del aprendizaje. Hoy en día, las redes neuronales pueden aprender a construir modelos informáticos altamente maleables. La salida de la red neuronal ya no es el resultado de una sola fórmula. Ahora utiliza operaciones extremadamente complejas. Un modelo de red neuronal lo suficientemente grande puede acomodar cualquier tipo de datos.
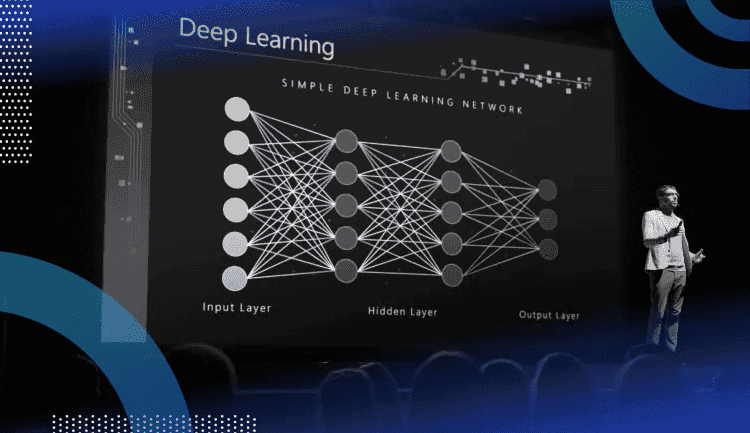
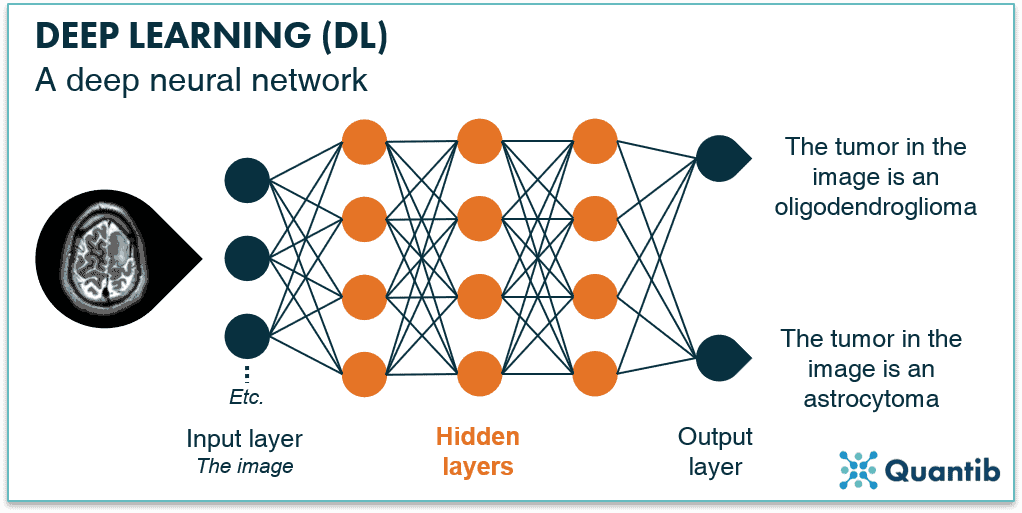
Hay una diferencia entre un “enfoque de sistemas expertos” y un “enfoque de sistemas flexibles”. Considere una situación en la que se usa una radiografía para determinar si un paciente tiene cáncer. La radiografía vendrá con varios componentes y características. Sin embargo, no sabremos cuáles de ellos son importantes.
Los sistemas expertos tratan el problema contando con expertos. En este caso, expertos en el campo de la radiología y la oncología. Especificarán las variables importantes y permitirán que el sistema examine solo esas variables. Este método requiere una pequeña cantidad de cálculo. Por lo tanto, ha sido ampliamente utilizado. Pero si los expertos no logran identificar las variables clave, entonces el sistema de informes fallará.
La forma en que los sistemas flexibles resuelven problemas es examinando tantas variables como sea posible. El sistema entonces decide por sí mismo cuáles son importantes. Esto requiere más datos y mayores costos computacionales. También es menos eficiente que los sistemas expertos. Sin embargo, con suficientes datos y cálculos, los sistemas flexibles pueden superar a los sistemas expertos.
Los modelos de aprendizaje profundo tienen parámetros enormes
Los modelos de aprendizaje profundo están “sobreparametrizados”. Esto significa que hay más métricas que puntos de datos disponibles para el entrenamiento. Por ejemplo, la red neuronal de un sistema de reconocimiento de imágenes puede tener 480 millones de parámetros. Sin embargo, se entrenará utilizando solo 1,2 millones de imágenes. Tener parámetros enormes a menudo conduce a un “sobreajuste”. Esto significa que el modelo se ajusta demasiado bien al conjunto de datos de entrenamiento. Por lo tanto, el sistema puede pasar por alto la tendencia general pero obtener los detalles.
Gizchina Noticias de la semana
El aprendizaje profundo ya ha mostrado sus talentos en el campo de la traducción automática. Al principio, el software de traducción traducía según reglas desarrolladas por expertos en gramática. Al traducir idiomas como el urdu, el árabe y el malayo, los métodos basados en reglas inicialmente superaron a los métodos de aprendizaje profundo basados en estadísticas. Pero a medida que crecen los datos de texto, el aprendizaje profundo ahora supera a otros métodos en todos los ámbitos. Resulta que el aprendizaje profundo es superior en casi todos los dominios de aplicación.
Enorme costo computacional
Una regla que se aplica a todos los modelos estadísticos es que para mejorar el rendimiento de K, se necesitan 2K de datos para entrenar el modelo. Además, existe un problema de parametrización excesiva del modelo de aprendizaje profundo. Por lo tanto, para aumentar el rendimiento en K, necesitará al menos 4 K de la cantidad de datos. En términos simples, para mejorar el rendimiento de los modelos de aprendizaje profundo, los científicos necesitan construir modelos más grandes. Estos modelos más grandes se utilizarán para entrenamiento. Sin embargo, ¿qué tan costoso será construir modelos más grandes para entrenamiento? ¿Será demasiado alto para pagarlo y así mantener el campo?
Para explorar esta pregunta, los científicos del Instituto de Tecnología de Massachusetts recopilaron datos de más de 1000 artículos de investigación de aprendizaje profundo. Su investigación advierte que el aprendizaje profundo enfrenta serios desafíos.
Tomemos como ejemplo la clasificación de imágenes. Reducir los errores de clasificación de imágenes da como resultado una enorme carga computacional. Por ejemplo, la capacidad de entrenar un sistema de aprendizaje profundo en una unidad de procesamiento de gráficos (GPU) se demostró por primera vez en 2012. Esto se hizo con el modelo AlexNet. Sin embargo, tomó de 5 a 6 días de entrenamiento usando dos GPU. Para 2018, otro modelo, NASNet-A, tenía la mitad de la tasa de error de AlexNet. Sin embargo, utilizó más de 1000 veces más cálculos.
¿La mejora en el rendimiento de los chips ha seguido el ritmo del desarrollo del aprendizaje profundo? en absoluto. Del aumento de más de 1000 veces en el cálculo de NASNet-A, solo una mejora de 6 veces proviene de un mejor hardware. El resto se logra usando más procesadores o funcionando por más tiempo, con costos más altos.
Los datos prácticos son mucho más que sus cálculos
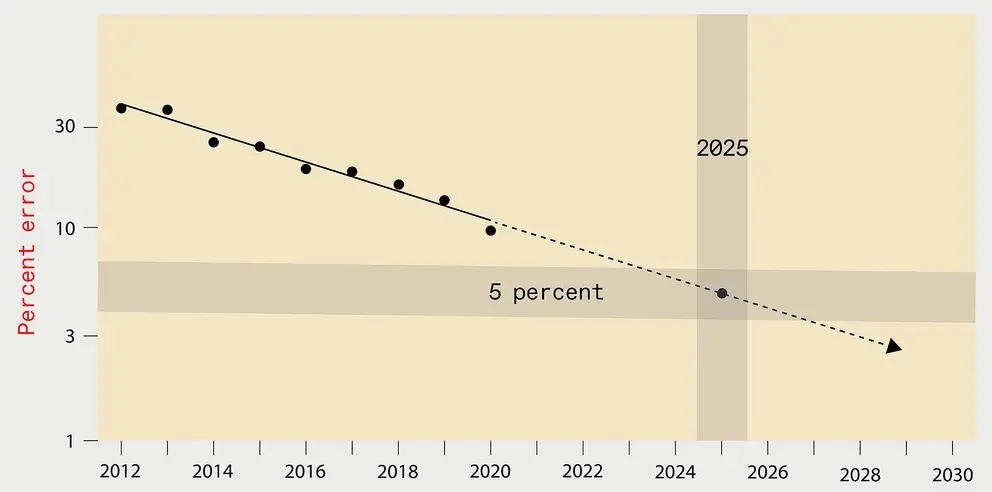
En teoría, para mejorar el rendimiento por un factor de K, necesitamos 4K más de datos. Sin embargo, en la práctica, el cálculo requiere un factor de al menos 9K. Esto significa que se requieren más de 500 veces más recursos informáticos para reducir la tasa de error a la mitad. Esto es bastante caro, la verdad es que es muy caro. Entrenar un modelo de reconocimiento de imágenes con una tasa de error inferior al 5 % costará 100 000 millones de dólares. La electricidad que consume generará emisiones de carbono equivalentes a un mes de emisiones de carbono en la ciudad de Nueva York. Si entrena un modelo de reconocimiento de imágenes con una tasa de error de menos del 1%, el costo es aún mayor.
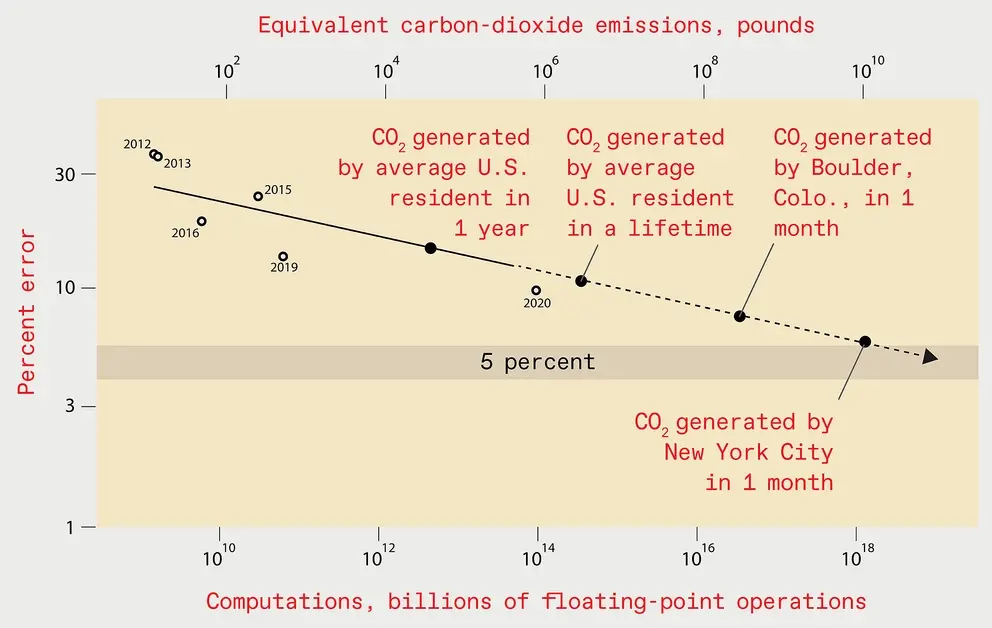
Para 2025, la tasa de error del sistema óptimo de reconocimiento de imágenes se reducirá al 5%. Sin embargo, entrenar un sistema de aprendizaje tan profundo generaría el equivalente a un mes de emisiones de dióxido de carbono en la ciudad de Nueva York.
La carga del costo computacional se ha hecho evidente en la vanguardia del aprendizaje profundo. IA abierta, un grupo de expertos en aprendizaje automático, ha gastado más de $ 4 millones en diseño y capacitación. Las empresas también están comenzando a rehuir el costo computacional del aprendizaje profundo. Una gran cadena de supermercados en Europa abandonó recientemente un sistema basado en el aprendizaje profundo. El sistema tenía que predecir qué productos se comprarían. Los ejecutivos de la empresa concluyeron que el costo de capacitación y mantenimiento del sistema era demasiado alto.